Openstack live migration failed after nova out of sync with current state
We recently had an issue where after live migrating instances off a host Openstack reported the migrations as failing however looking at the hosts throuh virsh the instance had migrated and was successfully running on the new hosts.
The cause of the failure was down to some config left referencing an old ceph pool. To resolve with Openstack reporting wrong we followed the instructions from Nova DB out of sync - VM not running on expected hypervisor which appeared to resolve the issue. A few days later when trying to move these VM's again we hit a different error.
Error: Failed to live migrate instance to host "AUTO_SCHEDULE". Details Compute host osw06.<SNIP> could not be found.
2021-10-01 02:33:36.798 2591145 ERROR nova.conductor.tasks.migrate [req-ab63e887-d6dd-4a9f-81df-4d78ca10af60 10380dffb91d4878a7446339e30ba87d 21449c46a90e4ab9aa59b0eac93e3731 - default default] [instance: 24e49e56-2c9a-443f-9e7c-5e6fc9fd34d5] Unable to find record for source node osw08.<SNIP> on osw06.<SNIP>: nova.exception.ComputeHostNotFound: Compute host osw06.<SNIP> could not be found.
2021-10-01 02:33:36.800 2591145 WARNING nova.scheduler.utils [req-ab63e887-d6dd-4a9f-81df-4d78ca10af60 10380dffb91d4878a7446339e30ba87d 21449c46a90e4ab9aa59b0eac93e3731 - default default] Failed to compute_task_migrate_server: Compute host osw08.<SNIP> could not be found.: nova.exception.ComputeHostNotFound: Compute host osw06.<SNIP> could not be found.
2021-10-01 02:33:36.801 2591145 WARNING nova.scheduler.utils [req-ab63e887-d6dd-4a9f-81df-4d78ca10af60 10380dffb91d4878a7446339e30ba87d 21449c46a90e4ab9aa59b0eac93e3731 - default default] [instance: 24e49e56-2c9a-443f-9e7c-5e6fc9fd34d5] Setting instance to ACTIVE state.: nova.exception.ComputeHostNotFound: Compute host osw06.<SNIP> could not be found.
TL;DR
The Suse documentation has the column host updated to the correct host. However there is another column that needs to be updated as well (column node)
Using a mysql query I was able to find 10 instances were affected. Updaing the node colument to match the host column then restarting the conductor process now appears to fix the issue and instances can be live migrated off the host.
MariaDB [nova]> select * from instances where host!=node;
<SNIP RESULTS>
10 rows in set (0.001 sec)
MariaDB [nova]> update instances set node = host;
Query OK, 10 rows affected (0.011 sec)
Rows matched: 79 Changed: 10 Warnings: 0
[root@osm01 ~]# systemctl restart openstack-nova-conductor.service
The process
The quick google search lead to some people having a similar issue where hosts were reporting down but everything else in the cluster appeared fine and I could migrate instances between other hosts.
[root@osm01 ~]# openstack compute service list
+----+----------------+----------------------------+----------+---------+-------+----------------------------+
| ID | Binary | Host | Zone | Status | State | Updated At |
+----+----------------+----------------------------+----------+---------+-------+----------------------------+
| 5 | nova-scheduler | osm01. | internal | enabled | up | 2021-10-02T05:35:58.000000 |
| 8 | nova-conductor | osm01. | internal | enabled | up | 2021-10-02T05:35:57.000000 |
| 14 | nova-compute | osw01. | nova | enabled | up | 2021-10-02T05:35:54.000000 |
| 15 | nova-compute | osw02. | nova | enabled | up | 2021-10-02T05:35:57.000000 |
| 16 | nova-compute | osw03. | nova | enabled | up | 2021-10-02T05:35:58.000000 |
| 17 | nova-compute | osw04. | nova | enabled | up | 2021-10-02T05:35:59.000000 |
| 18 | nova-compute | osw06. | nova | enabled | up | 2021-10-02T05:35:59.000000 |
| 19 | nova-compute | osw05. | nova | enabled | up | 2021-10-02T05:35:57.000000 |
| 20 | nova-compute | osw07. | nova | enabled | up | 2021-10-02T05:35:57.000000 |
| 21 | nova-compute | osw08. | nova | enabled | up | 2021-10-02T05:35:55.000000 |
+----+----------------+----------------------------+----------+---------+-------+----------------------------+
[root@osm01 ~]# nova hypervisor-list
+--------------------------------------+----------------------------+-------+---------+
| ID | Hypervisor hostname | State | Status |
+--------------------------------------+----------------------------+-------+---------+
| 9f1e0592-7f5e-4c34-9e04-b85b925ffa44 | osw01. | up | enabled |
| 0a16e729-0988-434d-bfc7-9a99171589d3 | osw02. | up | enabled |
| 46f54c0e-e3a7-4f57-b5f3-aec3d8c9153b | osw03. | up | enabled |
| 911c143a-278f-4ef0-b73c-8bab62692c44 | osw04. | up | enabled |
| 7cff68a5-d1dd-49e8-93c9-56091c975997 | osw06. | up | enabled |
| 453a5693-f50e-4745-a218-eed49a041e08 | osw05. | up | enabled |
| de6c6415-8f8a-4fe9-b4d7-ac051d16d863 | osw07. | up | enabled |
| 6d07654b-40dc-4847-848b-4aa0ddb10224 | osw08. | up | enabled |
+--------------------------------------+----------------------------+-------+---------+
After finding the exception nova.exception.ComputeHostNotFound and having a bit of a look around nothing jumped out. I ended up turning on mysql query logging and this query jumped out at me.
SELECT cn.created_at, cn.updated_at, cn.deleted_at, cn.deleted, cn.id, cn.service_id, cn.host, cn.uuid, cn.vcpus, cn.memory_mb, cn.local_gb, cn.vcpus_used, cn.memory_mb_used, cn.local_gb_used, cn.hypervisor_type, cn.hypervisor_version, cn.hypervisor_hostname, cn.free_ram_mb, cn.free_disk_gb, cn.current_workload, cn.running_vms, cn.cpu_info, cn.disk_available_least, cn.host_ip, cn.supported_instances, cn.metrics, cn.pci_stats, cn.extra_resources, cn.stats, cn.numa_topology, cn.ram_allocation_ratio, cn.cpu_allocation_ratio, cn.disk_allocation_ratio, cn.mapped
FROM compute_nodes AS cn
WHERE cn.deleted = 0 AND cn.host = 'osw06.<SNIP>' AND cn.hypervisor_hostname = 'osw08.<SNIP>' ORDER BY cn.id ASC
Stipping it back a bit and running it
MariaDB [nova]> SELECT cn.uuid, cn.hypervisor_hostname, cn.host_ip, cn.host FROM compute_nodes AS cn WHERE cn.deleted = 0;
+--------------------------------------+----------------------------+-------------+----------------------------+
| uuid | hypervisor_hostname | host_ip | host |
+--------------------------------------+----------------------------+-------------+----------------------------+
| 9f1e0592-7f5e-4c34-9e04-b85b925ffa44 | osw01. | 10.12.1.201 | osw01. |
| 0a16e729-0988-434d-bfc7-9a99171589d3 | osw02. | 10.12.1.202 | osw02. |
| 46f54c0e-e3a7-4f57-b5f3-aec3d8c9153b | osw03. | 10.12.1.203 | osw03. |
| 911c143a-278f-4ef0-b73c-8bab62692c44 | osw04. | 10.12.1.204 | osw04. |
| 7cff68a5-d1dd-49e8-93c9-56091c975997 | osw06. | 10.12.1.206 | osw06. |
| 453a5693-f50e-4745-a218-eed49a041e08 | osw05. | 10.12.1.205 | osw05. |
| de6c6415-8f8a-4fe9-b4d7-ac051d16d863 | osw07. | 10.12.1.207 | osw07. |
| 6d07654b-40dc-4847-848b-4aa0ddb10224 | osw08. | 10.12.1.208 | osw08. |
+--------------------------------------+----------------------------+-------------+----------------------------+
So that query will never return any results.
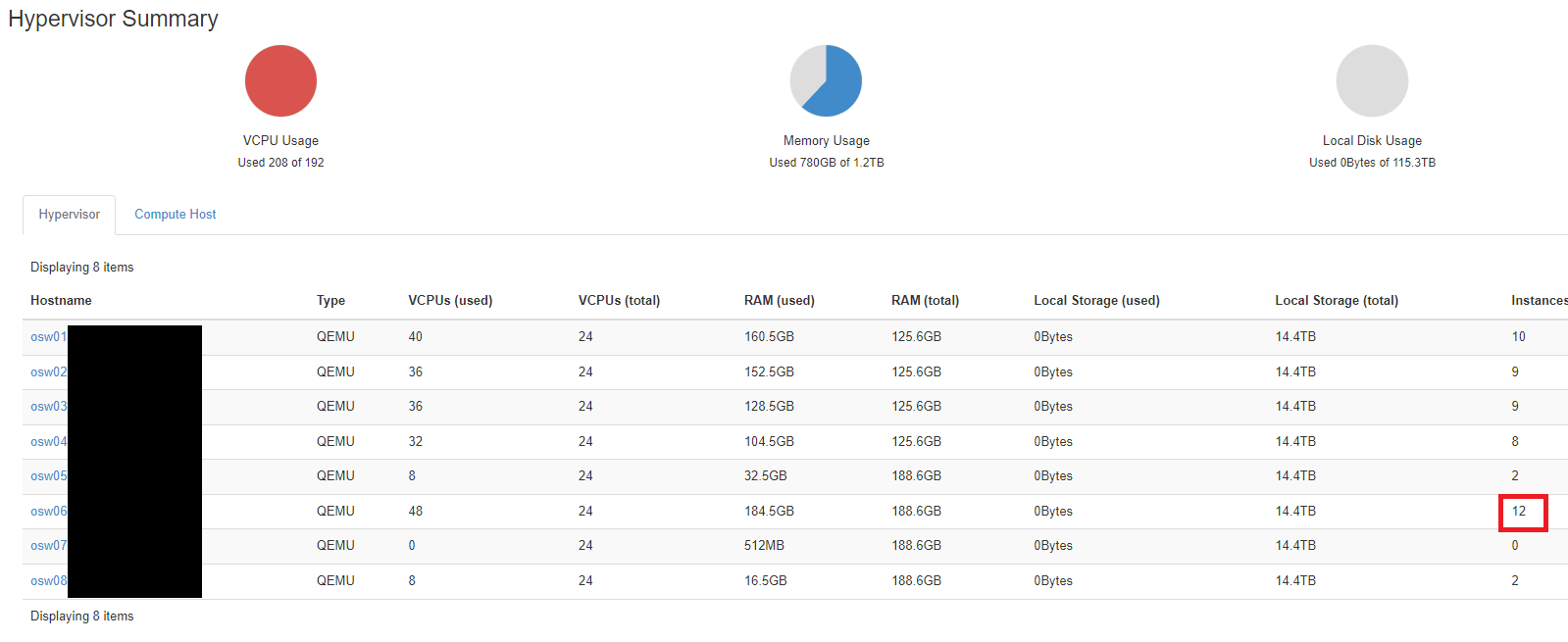
I also noticed that on the Admin > Instances of the list of hosts the instance count was showing 2 instances however through virsh 12 were running and if you look at the instance list for the host in horizon 12 were running.
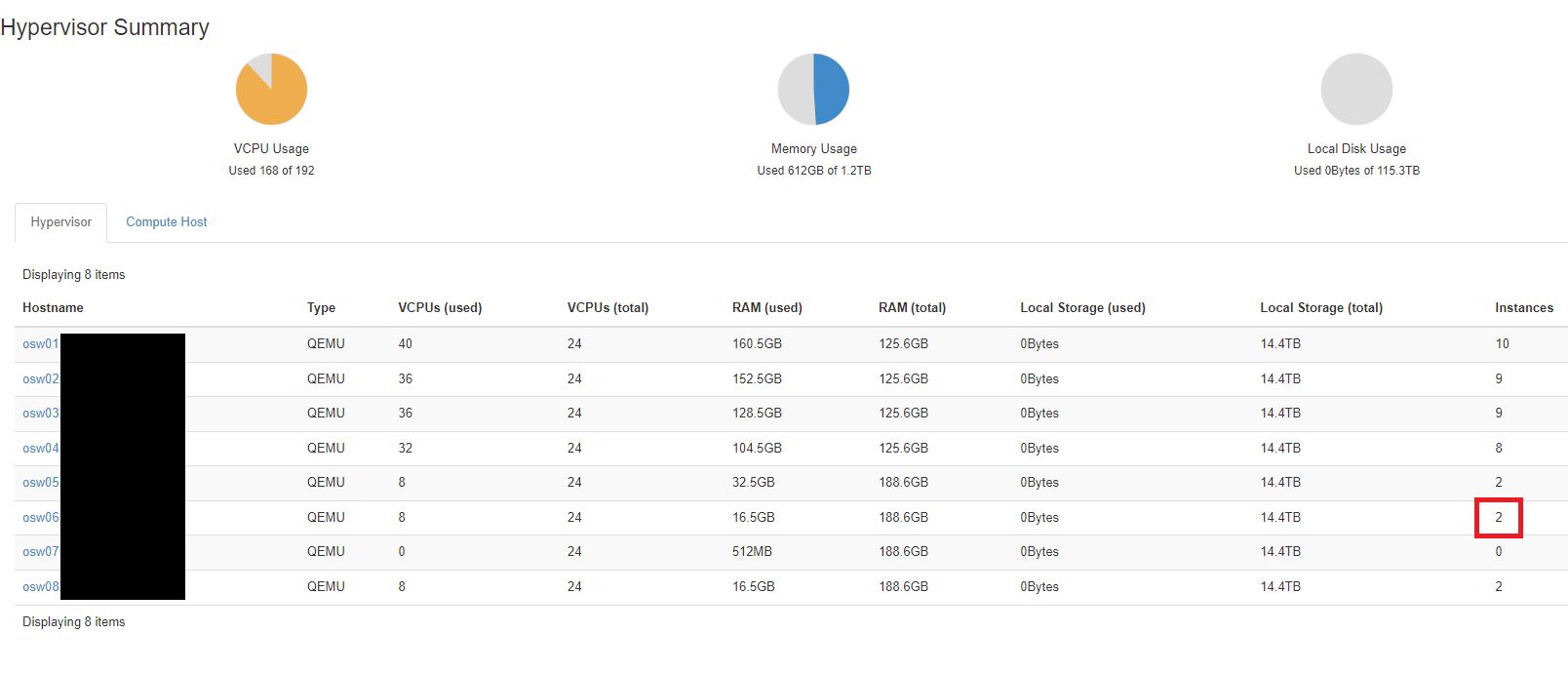
After some more poking around in the database is when I discovered both the host and node column on the instance table and that the affected instances were out of sync. Updating these columns to match reality resolved the issue.